Algorithm Workflow
Our multi-stage deep learning pipeline for Oral cancer detection
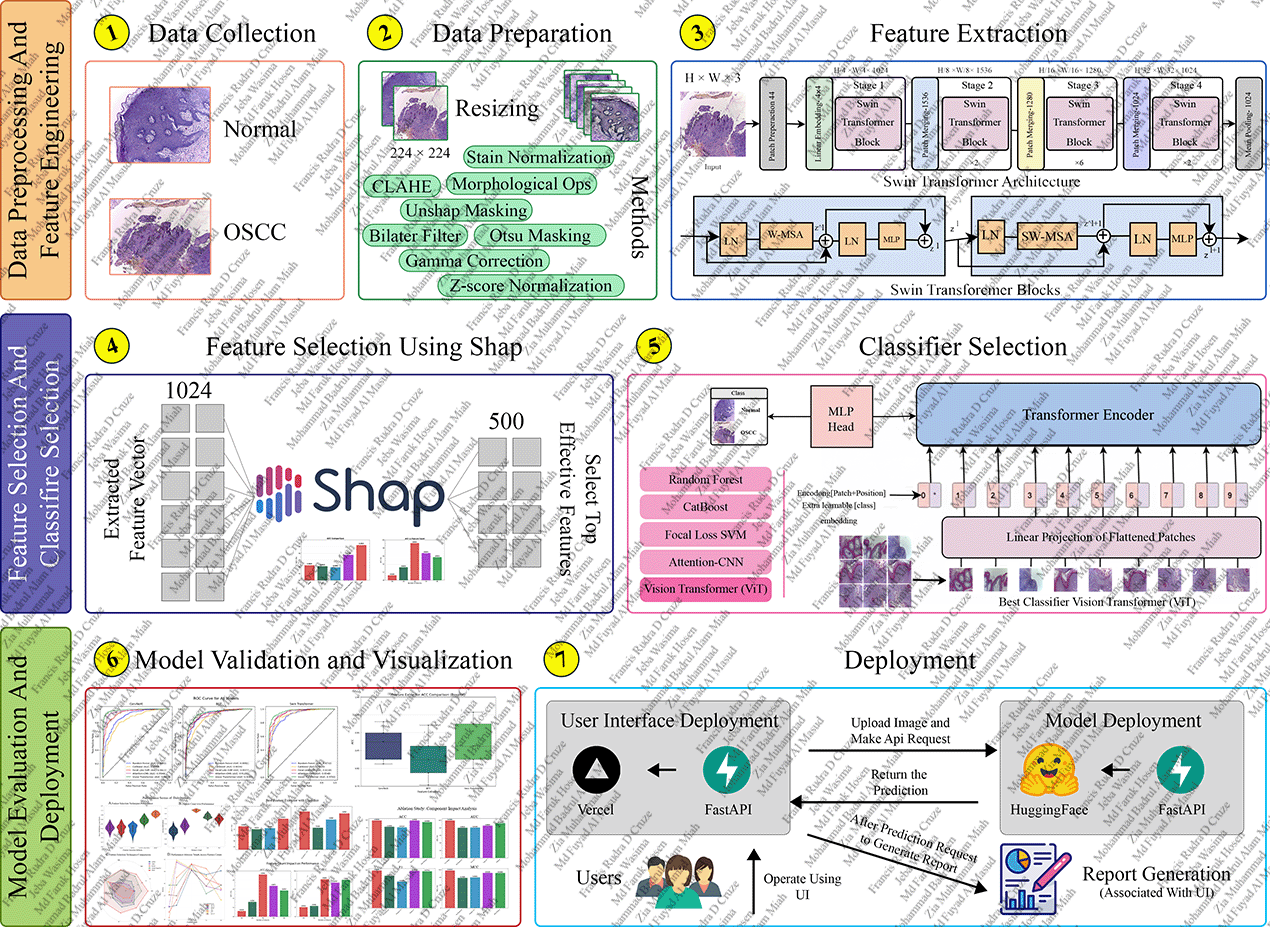
Figure 1: Overall pipeline of the proposed cancer classification framework, including data preprocessing, Swin Transformer feature extraction, SHAP-based feature selection, and Vision Transformer classification.
Methodology & Approach
Detailed breakdown of our multi-stage deep learning approach
Stage 1: Image Preprocessing
CLAHE (Contrast Limited Adaptive Histogram Equalization) for contrast enhancement
Bilateral filtering for noise reduction while preserving edges
Standardized resizing to 224x224 dimensions
Stage 2: Feature Extraction
Swin Transformer (Large) backbone with shifted window attention
Hierarchical representation (Patch size: 4, Window size: 7)
Extraction of 1024-dimensional high-level feature vectors
Stage 3: Feature Selection
SHAP (SHapley Additive exPlanations) analysis for feature importance
Genetic Algorithm and mRMR evaluation
Selection of optimal 500 features for maximum discrimination
Stage 4: Classification
Vision Transformer (ViT) Classifier (4 Layers, 8 Heads)
Multi-head Self-Attention mechanism for feature processing
High-precision prediction (99.25% Accuracy)
Key Innovations
Novel contributions and technological advances in our approach
Hybrid Swin-ViT architecture for capturing global and local dependencies
SHAP-guided feature optimization
Robust performance (99.25% Acc) exceeding ResNet and EfficientNet baselines
Explainable AI techniques for clinical trust
Technical Architecture
Deep learning components and model architecture details
Feature Extraction
Swin Transformer
Swin-Large model using shifted windows to model long-range dependencies efficiently
Patch Embedding
Decomposition of images into 4x4 patches for hierarchical processing
Feature Selection
SHAP Analysis
Game-theoretic approach to explain output of the feature extractor
Optimal Subset
Reduction to 500 most critical features to prevent overfitting
Classification
ViT Classifier
Proposed Vision Transformer head with 128 embedding dimension
Optimization
Training over 50 epochs with 0.0001 learning rate
Model Performance Metrics
Experience Our Algorithm in Action
Test our multi-stage deep learning approach with your own medical images or explore our sample dataset